





At The COVID Tracking Project, we report extensively on the hospitalization data we compile from US states and territories. Although many hospitalization metrics are inconsistently and incompletely reported at the state level, at least one of them, current COVID-19 hospitalizations, has been one of the best measures of what is actually happening on the ground throughout the pandemic’s ebbs and surges this year.
During the fall, a federal dataset that aggregates very similar current hospitalization data has become more consistent with the data we compile from states, particularly if we allow for known variations in state data definitions. We think this federal current hospitalization metric—which comes from the US Department of Health and Human Services and is published alongside several other potentially useful hospitalization figures that we can’t get from states—is a good candidate to use alongside and eventually in place of the state data we compile.
Comparing state data to the HHS data requires that we consider the inconsistent data definitions across US states and territories: Some jurisdictions report hospitalizations of confirmed COVID-19 patients only, others report hospitalizations for confirmed and suspected COVID-19 patients, others report a number without providing a data definition, and still others use an idiosyncratic definition. Taking into account this variance in data definitions—and a one-day lag, at the national/aggregate level, between CTP’s recording of state data and HHS data—we can see that these datasets present nearly identical information. Since November 8, making the same reasonable adjustments, the datasets have fallen within 2 percent of each other.
On July 7, HHS released this public dataset assembled via the department’s controversial new HHS Protect/Teletracking hospital reporting system. Over the summer, we reported on how we saw the state-reported hospital data we compiled temporarily degrade in quality as hospitals switched over from existing state and CDC systems to the new HHS system on a very short timeline. We expected that the state-reported hospitalization data would bounce back once hospitals had completed the training and process changes required to use the new systems, and they eventually did. State-reported hospital data is still far from perfectly standardized across US jurisdictions, but it recovered from the summer disruptions and remains one of our most reliable metrics.
We compared state and federal current hospitalization metrics, and we are now publishing the results of this analysis, along with recommendations of other HHS hospitalization data points that members of the media and public may find helpful. Before we dive into the analysis, a few notable points about the dataset and its history may be helpful.
What’s in the data
The public HHS hospitalization dataset currently includes the following categories of metrics (more detail is available in the "Columns in this Dataset" section of the dataset's landing page):
Current COVID-19 hospitalizations, disaggregated by confirmed and suspected patients in adult and pediatric settings
New COVID-19 hospital admissions, disaggregated by confirmed and suspected patients in adult and pediatric settings
Data on “hospital-onset COVID” patients—total current inpatients with suspected or laboratory-confirmed COVID-19 with onset 14 or more days after admission to the hospital for a condition other than COVID-19
Staffing shortage survey data, both for the current day and expectations for the week ahead
Inpatient and ICU capacity data
Facility-level metadata showing which hospitals report which metrics
HHS also offers a full historical time-series, published for the first time in November and updated regularly, but not daily, as well as public estimates that focus on hospital utilization. An analysis of HHS’s estimates or estimation processes is beyond the scope of this post.
Our analysis has focused on the relationship between state-reported current hospitalization metrics and their HHS counterparts, but once we established that the gaps between state and federal current hospitalization data were largely explained by accounting for variance in data definitions, we also began using the new admissions and hospital staffing shortage data within our own teams to provide additional context for the current hospitalization figures.
Where does the data come from?
The data that HHS publishes originates in hospital surveys, but that information can make its way into the federal database in two different ways. Hospitals that report directly to the government must use a portal developed by a contractor, TeleTracking. This data then drops into the HHS Protect data management system developed by Palantir. Not all hospitals report directly, however. In many cases, HHS has certified states (or state hospital associations) to collect data on behalf of their hospitals and then submit it through Teletracking or HHS Protect. This full data is compiled and analyzed by a team within HHS called the Data Strategy and Execution Workgroup. It is made available internally to the federal government’s COVID-19 response agencies including the US Centers for Disease Control and Prevention, the US Centers for Medicare & Medicaid Services, the Federal Emergency Management Agency, and the Office of the Assistant Secretary for Preparedness and Response. A subset of the data is then uploaded to Healthdata.gov.
Is the data trustworthy?
For the first few months after its publication, the HHS current hospitalizations data was relatively incomplete, and it sometimes deviated significantly from what states reported. Over time, however, the HHS data has become much more complete. In July, fewer than three-quarters of hospitals were reporting on a daily basis, and almost none were reporting all of the data fields in a given week. By November, nearly 100 percent of hospitals were reporting daily, and roughly 90 percent were reporting all the fields each week. HHS now provides hospital-level metadata about this reporting quality.
Now, when we look at state-reported data and compare it to the Federal system, we see that it corresponds very closely, when state data definitions are properly accounted for. In the image below, we see the two aggregate datasets graphed against each other. When all hospitalizations are counted, the HHS dataset consistently outstrips the CTP dataset because some states do not report suspected COVID-19 cases in hospitals, which means our data doesn’t capture those. When we look at the HHS data for confirmed cases against the CTP dataset, we see they are also extremely similar.
Looking at the 50 states, plus the District of Columbia and Puerto Rico, we found the data matched closely in 41 of the 52 jurisdictions. In seven cases—Delaware, North Dakota, Nevada, New York, Oregon, Pennsylvania, and Wisconsin—the state data is lower than we would expect, based on what we know about the state’s reporting. This is probably because of variation in state data definitions, such as using a more restrictive criteria for counting a COVID-19 hospitalization, or unknown reporting quirks. In two states—Kansas and Montana—the data is too messy to quite call it a match. Only two states regularly show a higher count in the CTP dataset than the HHS one (New Mexico and Mississippi). In every single case, the CTP and HHS datasets move in concert.
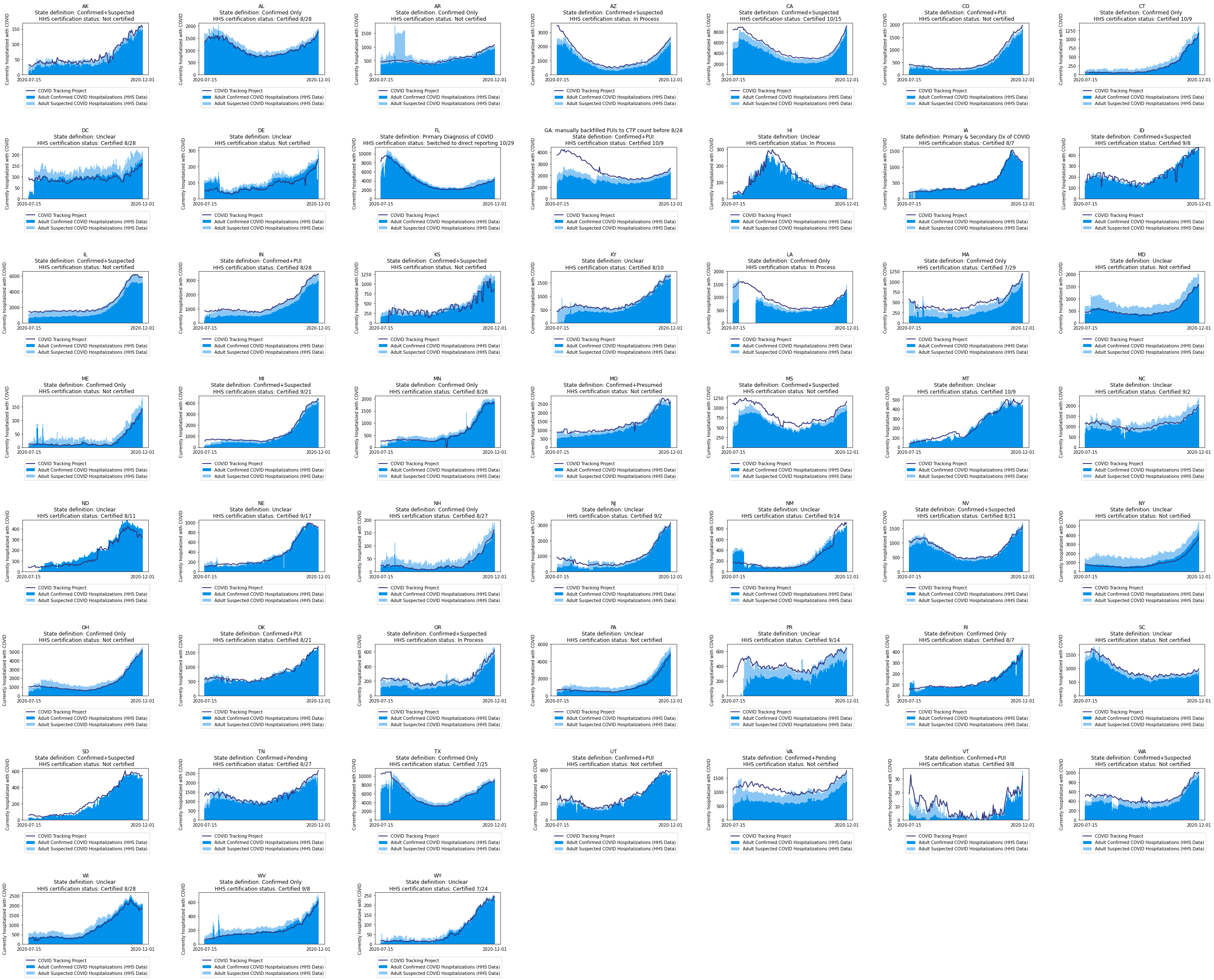{kind=link}
The HHS data on new admissions—that is, people newly entering the hospital— likewise bears a strong and logically consistent relationship to the current hospitalization data we compile from states.
When we look at this hospital admissions data, we do not have a corollary measurement from states. But it turns out that, as one might expect, cases and admissions track very closely. When we plot them together, they behave in almost identical ways. This makes sense. As infections spread, some subset of them are confirmed as cases through testing, while a smaller subset of severe illnesses show up in the data on hospital admissions. Because of the variability of state data-reporting pipelines, there is wide variation between states in the temporal relationship between case and admissions data. But in the national aggregate, cases and admissions rise in near-lockstep.
Because of the close match between state-reported and HHS data for these metrics, we have no reason to believe that the federal data on current hospitalizations or hospital admissions are in any way manipulated by political concerns. Some commentators expressed concern that data compiled inside HHS’s core (and not at the CDC) would be shaped by political considerations. Given the influence that the Trump administration’s political appointees exerted within HHS, these worries were understandable, and we took this possibility seriously throughout our months-long engagement with this dataset. That this manipulation did not happen, as far as anyone has been able to show, is a win for the country’s public health infrastructures.
The federal data set also comes with several added benefits:
It includes metadata on how many hospitals report on a given day (most states don’t offer this information).
It is built around relatively consistent—and, importantly, public—data definitions, whereas many states do not provide the detailed data definitions needed to contextualize daily metrics.
It is frequently more inclusive than state hospitalization numbers, because they count suspected COVID-19 hospital patients, a patient group many states elect not to count in public data.
That said, we aren’t in a position to evaluate many of the metrics included in the HHS dataset. Hospital capacity metrics—like “total staffed inpatient beds,” for example—are dynamic measures with specialized definitions intended for data users with shared context and specific expertise. Whether they’re drawn from state or federal sources, these metrics have proven difficult to use in communications with the public, and we recommend that media organizations relying on capacity statistics of any kind speak with informed public health sources and with hospital staff to contextualize the data.
Note: Although some analyses have called the HHS dataset into question, another independent analysis presented to the agency’s modelers supports our position that the metrics in the HHS dataset that we are able to evaluate appear to be at least as accurate and reliable as the state data.

Rebecca Glassman has a Master’s in Public Health and is a public health researcher in academia. Opinions expressed are her own.

Erin Kissane is a co-founder of the COVID Tracking Project, and the project’s managing editor.

Dave Luo has an MD/MBA and is a Data Science and Data Viz lead at The COVID Tracking Project.

Alexis C. Madrigal is a staff writer at The Atlantic, a co-founder of the COVID Tracking Project, and the author of Powering the Dream: The History and Promise of Green Technology.

Peter Walker is Head of Marketing & Growth at PublicRelay and Data Viz Co-Lead at The COVID Tracking Project.
More “Hospitalization and Death Data” posts
20,000 Hours of Data Entry: Why We Didn’t Automate Our Data Collection
Looking back on a year of collecting COVID-19 data, here’s a summary of the tools we automated to make our data entry smoother and why we ultimately relied on manual data collection.

A Wrap-Up: The Five Major Metrics of COVID-19 Data
As The COVID Tracking Project comes to a close, here’s a summary of how states reported data on the five major COVID-19 metrics we tracked—tests, cases, deaths, hospitalizations, and recoveries—and how reporting complexities shaped the data.


How Lagging Death Counts Muddled Our View of the COVID-19 Pandemic
During the worst parts of the COVID-19 pandemic, the United States struggled to keep up with COVID-19 death counts.